
Sprawdź swoją stronę
Niektóre instytucje publiczne, organizacje, redakcje czasopism naukowych, media czy twórcy internetowi mogą być zainteresowani tym, aby publikowane przez nich strony mogły być skutecznie zarchiwizowane i dostępne w archiwach Webu także wtedy, kiedy przestaną już funkcjonować pod oryginalnymi domenami.
-
- Wejdź na stronę aplikacji ArchiveReady.
- Wklej do formularza adres swojej strony (adres strony głównej).
- Aplikacja zanalizuje kod strony i jej zawartość.
- Otrzymasz informację zwrotną m.in. w postaci ogólnej oceny wyrażonej w procentach (Overall Rating).
-
- Ocena ogólna (Overall Rating) może być przydatna przy porównywaniu różnych witryn. Ponieważ aplikacja ArchiveReady udostępnia API, można w prosty sposób automatycznie porównać wiele witryn.
- Aplikacja analizuje też szczegółowe wymiary potencjału archiwalnego witryny (web archivability): dostępność (interpretowana z perspektywy osób niepełnosprawnych, accessibility), spójność (cohesion), dostępność metadanych (metadata) oraz zgodność ze standardami pisania stron WWW (standards compliance).
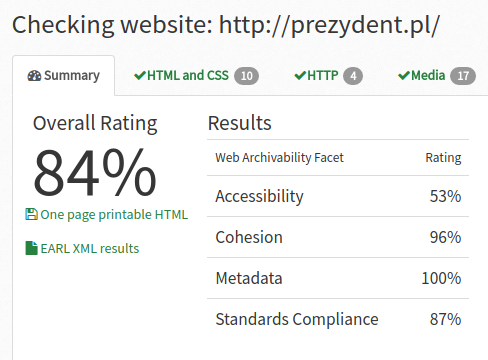
- Aplikacja udostępnia także szczegółowe informacje o błędach, które należałoby poprawić, aby zwiększyć potencjał archiwalny witryny. Informacje te prezentowane są w zakładkach HTML and CSS (analiza błędów w kodzie strony i w kodzie arkusza stylów), HTTP (analiza błędów w nagłówkach HTTP wysyłanych przez serwer), Media (analiza błędów związanych z dostępnością i prezentowanistrong mediów w witrynie), Sitemaps (analiza dostępności i jakości map strony).

-
- Aplikacja sczytuje testowaną stronę, a następnie analizuje jej strukturę pod kątem poprawności kodu i zgodności kodu ze standardami, analizuje poprawność (aktualność) linków wewnętrznych, analizuje poprawność nagłówków HTTP, sprawdza obecność bibliotek zewnętrznych (java script, css), które są wczytywane podczas ładowania strony, sprawdza szybkość ładowania strony, bada obecność map witryny (sitemaps).
- Strona kopiowana jest automatycznie do archiwum Webu przez robota internetowego (crawler). Jeśli w trakcie generowania strony przez bota pojawią się błędy wynikające z jej niewłaściwej konstrukcji i błędnego kodu, kopia zachowana w archiwum będzie niskiej jakości.
- Jeśli witryna nie będzie udostępniać poprawnej mapy strony i publikować błędne (nieaktualne) linki, istnieje możliwość, że crawler nie dotrze do wszystkich stron.
- Jeśli witryna korzystać będzie z zewnętrznych bibliotek (np. bibliotek java script czy css publikowanych na niezależnych domenach), istnieje niebezpieczeństwo, że robot nie będzie w stanie zarchiwizować tych bibliotek lub po latach, kiedy strona będzie wyświetlana w archiwum Webu, biblioteki te nie będą już dostępne.
- Najlepszym sposobem na zwiększenie potencjału archiwalnego witryny jest respektowanie standardów tworzenia stron WWW oraz dbanie o jej integralność i dostępność.
-
Autor aplikacji, Vangelis Banos, opublikował kilka artykułów naukowych poświęconych swojej metodzie oceny potencjału archiwalnego witryny internetowej:
- Banos V., Manolopoulos Y., Web Content Management Systems Archivability, ADBIS 2015.
- Banos V., Manolopoulos Y.: A quantitative approach to evaluate Website Archivability using the CLEAR+ method, International Journal on Digital Libraries, 2015, Springer Link.
- Banos V., Kim Y., Ross S., Manolopoulos Y.: CLEAR: a credible method to evaluate website archivability, iPRES 2013.
-
- Zapytanie:
curl http://archiveready.com/api?url=http://prezydent.pl - Odpowiedź w formacie JSON ze szczegółowymi danymi analizy witryny.
- Zapytanie: