
Newsletter #3 – 15.02.2024
Zapraszamy do zapoznania się z nowym numerem newslettera naukowego Pracowni Archiwistyki Webu CKC UW.
Koniec kopii stron w wynikach wyszukiwania Google
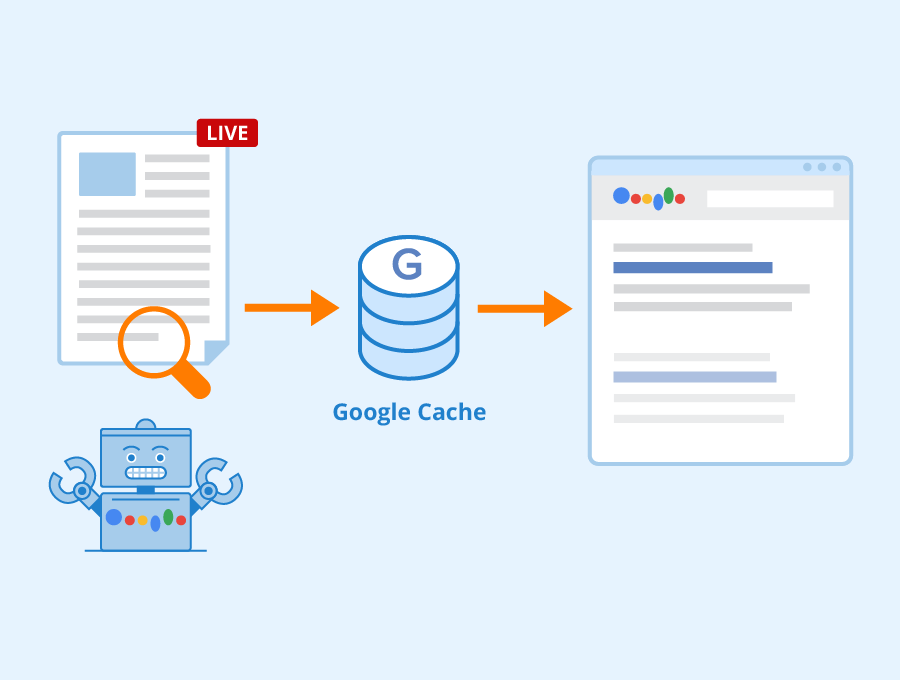
Google usunęło możliwość korzystania z kopii (cache) stron internetowych, indeksowanych w swoim katalogu. Danny Sullivan, odpowiedzialny w Google za kształt narzędzia wyszukiwania, wyjaśnił, że zapisywanie indeksowanych stron w cache miało pierwotnie ułatwiać dostęp do ich treści w sytuacji problemu z serwerem wydawcy czy innymi błędami uniemożliwiającymi wyświetlenie strony w przeglądarce. Według Google stabilność indeksowanych stron uległa znacznej poprawie, co skłoniło firmę do podjęcia decyzji o wycofaniu tego narzędzia.
Cache to pamięć podręczna, czyli rodzaj bufora używanego do tymczasowego przechowywania danych w celu przyspieszenia dostępu do nich. Cache może być wykorzystywane przez przeglądarki internetowe do przechowywania kopii stron internetowych lub pewnych ich elementów, co umożliwia szybsze ładowanie strony przy kolejnych odwiedzinach.
Rezygnacja generowania kopii cache przez Google to kolejne wyzwanie dla stabilności zasobów Webu.
https://arstechnica.com/gadgets/2024/02/google-search-kills-off-cached-webpages/
Pismo o polskim dziedzictwie cyfrowym
Polskie Towarzystwo Ochrony Dziedzictwa Technicznego publikuje drukowane czasopismo „Grel”. Tytuł pisma nawiązuje do lat 70./80., gdy w polskiej informatyce forsowano polską terminologię komputerową. Jak czytamy w niedawnym newsletterze Towarzystwa, „Grel to słowo, które miało zastąpić angielskie pixel, a powstało ze złączenia liter gr i el, a te są pierwszymi literami wyrazów graficzny oraz element”.
Celem stowarzyszenia Polskie Towarzystwo Ochrony Dziedzictwa Technicznego jest dbałość o materialne i niematerialne, w tym cyfrowe, dziedzictwo techniczne i kulturowe, podejmowanie działań na rzecz zachowania urządzeń technicznych, dokumentów, procesów, dzieł cyfrowych oraz wiedzy technicznej dla następnych pokoleń, upowszechnianie i pogłębianie wiedzy z zakresu historii nauki i techniki, szczególnie wśród dzieci i młodzieży.
https://ptodt.org.pl/publikacje/grel/
CFP: Rekonstruowanie sieci komputerowych Europy Wschodniej i Środkowej: Od upadku bloku sowieckiego do wojny Rosja-Ukraina
Na stronach czasopisma naukowego “Internet Histories” opublikowano CFP do numeru poświęconego historii internetu i Webu w Europie Środkowej i Wschodniej. Tematy opracowań proponowane przez redakcję to:
- Społeczno-techniczno-historyczne podejścia do sieci komputerowych i infrastruktur w Związku Radzieckim oraz Europie Wschodniej i Środkowej
- Cybernetyczne historie i dziedzictwo (m.in. sowieckie)
- Upadek Związku Radzieckiego oraz prywatyzacja lub nieprywatyzacja infrastruktur internetowych
- Infrastruktury telekomunikacyjne i internetowe w krajach Europy Środkowo-Wschodniej i ich podział lub związki z dziedzictwem sowieckim
- Zmiany technologiczne infrastruktury internetowej wywołane wojną
- Lokalne historie i precyzyjne studia przypadków dotyczące internetu w Europie Środkowo-Wschodniej
- Metodyczne podejścia do badania infrastruktur internetowych i telekomunikacyjnych w Europie Środkowo-Wschodniej
https://think.taylorandfrancis.com/special_issues/computer-networks-east-central-europe/
Archiwistyka Webu częścią metod badań cyfrowych
Metody archiwistyki Webu i zasady korzystania z narzędzi pozwalających na eksplorowanie archiwów WWW zostały przywołane w drugim wydaniu Doing Digital Methods Richarda Rogersa (wyd. Sage Publishing). Książka ma pomóc w prowadzeniu badań i analiz platform internetowych – oprócz wątku archiwistyki Webu znajdziemy tam rozdziały poświęcone krytyce mediów społecznościowych, badaniu algorytmów filtrowania i wyszukiwania czy analizowaniu haseł Wikipedii.
https://us.sagepub.com/en-us/nam/doing-digital-methods/book276577#contents
WARC-GPT: Otwarte narzędzie do badania archiwów internetowych przy użyciu sztucznej inteligencji
WARC-GPT umożliwia tworzenie niestandardowych czatbotów, które wykorzystują zestaw plików archiwum internetowego jako swoją bazę wiedzy, pozwalając użytkownikom eksplorować zbiory w ramach dialogu podobnego do tego znanego choćby z popularnego Chat GPT.
WARC-GPT umożliwia użytkownikom konwersję i adaptację zbioru plików WARC do konfiguracji RAG, która może być używana z różnymi modelami języka maszynowego. W ten sposób umożliwia archiwistom i badaczom korzystanie z czatbota, który posiada wiedzę na temat ich kolekcji. Szczególnie przydatne jest to w przypadku eksploracji prywatnych kolekcji plików WARC lub tych, które nie zostały uwzględnione w danych treningowych dla modeli języka maszynowego. Mimo że modele te zazwyczaj trenowane są na danych z Common Crawl (otwarte repozytorium danych z przeglądania stron internetowych obejmujące ponad 250 miliardów stron) niemożliwe jest zweryfikowanie, jakie dokładnie dane zostały uwzględnione. Wykorzystanie kolekcji plików WARC jako podstawy wiedzy dla modeli języka maszynowego dostarcza istotnych informacji kontekstowych, co jest szczególnie pomocne przy specyficznych zapytaniach w określonej dziedzinie.
Narzędzie zostało opracowane w ramach Library Innovation Lab na Harvardzie.
„New York Times” ma nie być archiwizowany w Wayback Machine
„New York Times” próbował zablokować boty Internet Archive, wysyłające poszczególne strony WWW do archiwizacji w Wayback Machine. W 2021 roku do pliku robots.txt, definiującego zasady indeksowania witryny, dodano blokadę dla botów „ia_archiver”.
Wayback Machine od dawna wykorzystywane jest także do porównywania różnych wersji tych samych stron internetowych. System WM pozwala na wskazanie różnic między każdą wersją. Narzędzie to może być używane np. do odkrywania zmian w treści artykułów, które zostały dokonane bez umieszczenia w ich treści notatek redakcyjnych informujących o zmianach w tekście (tzw. stealth editions).
W przeszłości „New York Times” był publicznie krytykowany za ukrywanie edycji swoich opublikowanych już online tekstów. Na przykład w 2016 roku gazeta znacząco zmieniła artykuł dotyczący ówczesnego kandydata na prezydenta ze strony Demokratów, senatora Berniego Sandersa. W ramach edycji pochwalny ton artykułu zmieniono na na sceptyczny. Spotkało się to z falą krytyki ze strony innych mediów, ale także samego redaktora „The Times”. Edycję ujawniono dzięki pracy blogera, który udokumentował ją z wykorzystaniem Wayback Machine.
W 2017 roku Internet Archive ogłosiło, że będzie w selektywny sposób respektować blokady dla swoich botów zapisywane w plikach robots.txt, szczególnie dla witryn rządowych i wojskowych. Strony „The Times”, nawet jeśli bywają archiwizowane, są następnie selektywnie usuwane ze zbiorów Internet Archive w ramach bezpośrednich interwencji redakcji tej gazety.
https://theintercept.com/2023/09/17/new-york-times-website-internet-archive/
Marcin Wilkowski (m.wilkowski@uw.edu.pl)
Grafika użyta na stronie: CC BY-SA Seobility