
Czy archiwalny Web wymaga archiwalnych przeglądarek?
Pewnie nie tylko w praktyce archiwialnej pojawia się pewne napięcie między obiektem z przeszłości a współczesną formą jego udostępniania. Jak bardzo oglądanie średniowiecznych manuskryptów na mikrofilmach zubaża ich odczytanie i zrozumienie? Czy klasyczne dzieło malarskie powinno być prezentowane wyłącznie w historycznych przestrzeniach? W jaki sposób skan 3D formatuje odczytanie i zrozumienie zabytku archeologicznego, skoro uniemożliwia doświadczenie jego materialności, ciężaru czy faktury? Podobne pytania zadawać można w kontekście dziedzictwa cyfrowego – badacze i instytucje zajmujące się dziedzictwem oprogramowania, gier komputerowych czy archiwami Webu dostrzegają problem współczesnego pośrednictwa. Gra z lat 80., w którą gra się na współczesnym jej sprzęcie jest przecież doświadczeniem bardzo różnym od tego, który doznajemy emulując tę grę w najnowszym systemie operacyjnym na naszym komputerze – stąd starania o to, aby archiwizując gry (czy w ogóle oprogramowanie), gromadzić i zabezpieczać historyczny sprzęt umożliwiający ich uruchomienie w oryginalnym środowisku.
Dominująca praktyka archiwów Webu polega dziś wciąż na gromadzeniu, przechowywaniu historycznych kopii witryn oraz udostępnianiu ich w najbardziej użyteczny dla odbiorców sposób: jako publicznego archiwum z interfejsem graficznym, nawigowalnego przez współczesne przeglądarki. Historyczne kopie stron są w takim przypadku wyświetlane za pomocą ahistorycznego narzędzia i w taki sposób odczytuje je i analizuje użytkownik. Taki stan nie musi być poważną przeszkodą dla kogoś, komu zależy przede wszystkim na informacyjnym wykorzystaniu archiwalnych kopii – kiedy kopie stron z Wayback Machine stają się elementem zestawu dowodów w sprawach sądowych nie ma znaczenia, za pomocą jakich narzędzi się je wyświetla. Jednak kiedy chcielibyśmy bardziej subtelnie podejść do strony WWW jako źródła historycznego, dostęp za pomocą historycznych przeglądarek mógłby być niezbędny.
Prowadzony przez fundację RHIZOME projekt oldweb.today pozwala na oglądanie archiwalnych kopii witryn internetowych w emulowanych historycznych przeglądarkach. Do dyspozycji mamy przeglądarkę Mosaic, Netscape Navigator oraz stare wersje Internet Explorera. Witryny wyświetlane w tych przeglądarkach pobierane są z kilkunastu archiwów Webu z wykorzystaniem protokołu Memento.
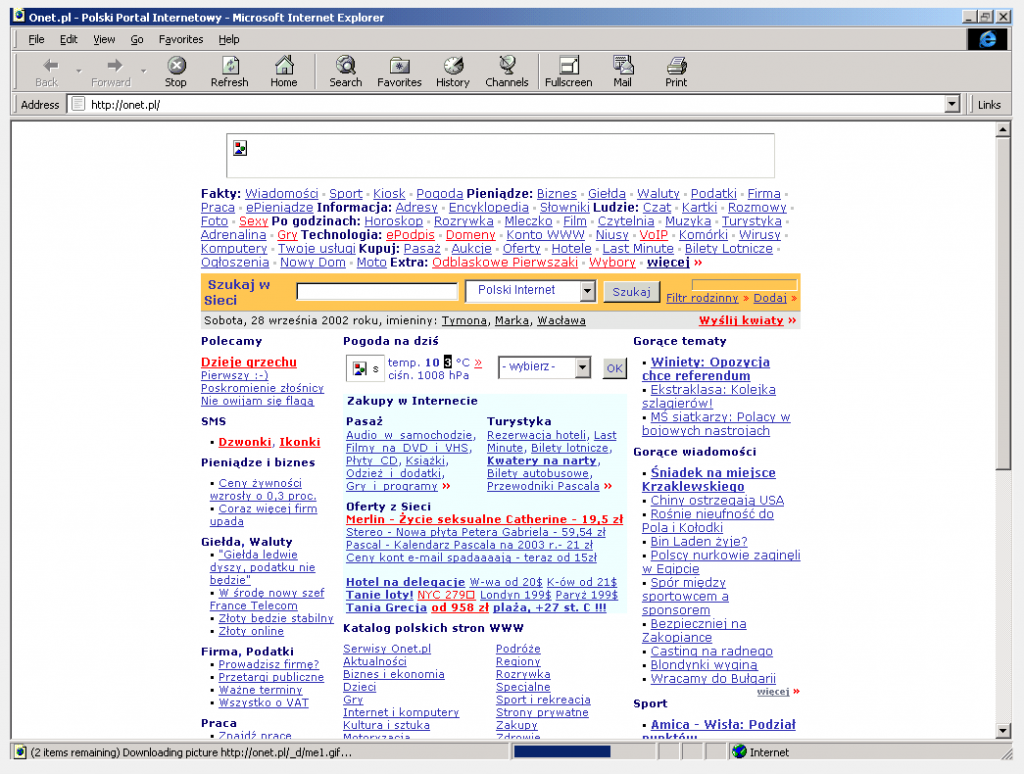
Języki pisania stron internetowych nieustannie ewoluują, a ich poszczególne elementy zyskują lub tracą wsparcie ze strony przeglądarek; wyświetlanie kopii archiwalnej w ahistorycznej przeglądarce może generować błędy, powodować ukrycie pewnych informacji lub elementów interfesju użytkownika itp., co wydaje się dość dużym ograniczeniem choćby w projektach badawczych netartu. Do tego korzystanie ze starych, historycznych przeglądarek pozwala doświadczyć ich ograniczeń związanych np. z szybkością wyświetlania strony i poruszania się po jej strukturze czy dostępnością lub niedostępnością określonych narzędzi przeglądania (np. zakładek).