
Ograniczenia jakości archiwów Webu budowanych metodą crawlingu
Autorzy artykułu, z których większość związana jest z Max-Planck-Institut für Informatik w Saarbrücken, zwracają uwagę na istotną wadę archiwizowania witryn WWW przy użyciu metody crawlingu.
W tej metodzie oprogramowanie sczytuje i archiwizuje po kolei powiązane ze sobą strony internetowe, podążając za linkami w treściach tych witryn (tzw. breadth-first-search, BFS crawling). Jak piszą badacze, idealnym efektem pracy archiwisty Webu byłoby pozyskanie 1:1 kopii całej witryny, a więc zamrożenie jej poszczególnych podstron tak, aby żadna z nich nie mogła zmienić się w trakcie trwającego niekiedy godziny, a czasem dni kopiowania. Ponieważ crawler nie może bez przerwy kopiować kolejnych stron – bo grozi to blokowaniem serwera z powodu zbyt dużej i częstej liczby zapytań – pozyskiwane do archiwum strony mogą zmieniać swoją treść w trakcie całego procesu. W rezultacie np. kopia witryny przypisana do konkretnej daty może (17 sierpnia 2018) zawierać podstrony publikowane później (w tym przypadku np. już 18 sierpnia). To ograniczenie może mieć negatywny wpływ na jakość analiz archiwów dokumentujących określone wydarzenia polityczne czy społeczne, w których różnica nawet jednego dnia może być znacząca.
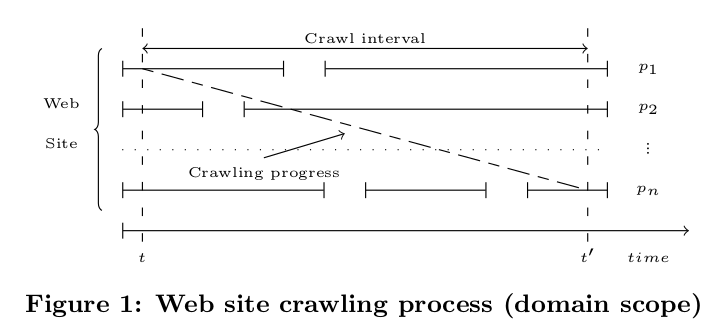
W swojej pracy autorzy prezentują model crawlingu mający pozwalać na zminimalizowanie ryzyka takiej niekoherencji. W dużym skrócie, jeżeli archiwizowana strona informuje precyzyjnie o czasie aktualizacji treści (precise time stamps), co jest powszechne np. przy serwisach newsowych czy blogach), jakość archiwizowanych stron może być poprawiana dzięki wyliczaniu prawdopodobieństwa ich zmiany w trakcie sesji crawlingowej i ułożenie ich w porządku malejącym na liście adresów do sczytania. Jeśli jednak nie są dostępne szczegółowe dane o czasie aktualizacji, propozycja autorów to wyliczanie (za pomocą określonego modelu) wirtualnych znaczników czasu i na ich podstawie szeregowanie adresów w kolejce do archiwizacji.